
이전 포스팅까지의 절차로 코랩 환경에서의 머신러닝 준비가 완료되었습니다.
이제 라벨링한 파일들을 토대로 직접 커스텀 모델을 만들 차례입니다.
3.1 라벨링 파일 전처리
첫 번째 포스팅에서 이미지 파일을 YOLO 포맷에 맞도록 라벨링 하였고 해당 파일을 불러오도록 train 파일과 test 파일을 나누어 전체적인 경로에 대해 따로 txt 파일을 만들도록 합니다.
import os
current_path = os.path.abspath(os.curdir)
COLAB_DARKNET_ESCAPE_PATH = '/content/gdrive/My\ Drive/darknet' #-- 본인 환경에 맞게 경로 변경할 것
COLAB_DARKNET_PATH = '/content/gdrive/My Drive/darknet' #-- 본인 환경에 맞게 경로 변경할 것
YOLO_IMAGE_PATH = current_path + '/custom' #-- 본인 환경에 맞게 경로 변경할 것
YOLO_FORMAT_PATH = current_path + '/custom' #-- 본인 환경에 맞게 경로 변경할 것
class_count = 0
test_percentage = 0.2
paths = []
with open(YOLO_FORMAT_PATH + '/' + 'classes.names', 'w') as names, \
open(YOLO_FORMAT_PATH + '/' + 'classes.txt', 'r') as txt:
for line in txt:
names.write(line)
class_count += 1
print ("[classes.names] is created")
with open(YOLO_FORMAT_PATH + '/' + 'custom_data.data', 'w') as data:
data.write('classes = ' + str(class_count) + '\n')
data.write('train = ' + COLAB_DARKNET_ESCAPE_PATH + '/custom/' + 'train.txt' + '\n')
data.write('valid = ' + COLAB_DARKNET_ESCAPE_PATH + '/custom/' + 'test.txt' + '\n')
data.write('names = ' + COLAB_DARKNET_ESCAPE_PATH + '/custom/' + 'classes.names' + '\n')
data.write('backup = backup')
print ("[custom_data.data] is created")
os.chdir(YOLO_IMAGE_PATH)
for current_dir, dirs, files in os.walk('.'):
for f in files:
if f.endswith('.jpg'):
image_path = COLAB_DARKNET_PATH + '/custom/' + f
paths.append(image_path + '\n')
paths_test = paths[:int(len(paths) * test_percentage)]
paths = paths[int(len(paths) * test_percentage):]
with open(YOLO_FORMAT_PATH + '/' + 'train.txt', 'w') as train_txt:
for path in paths:
train_txt.write(path)
print ("[train.txt] is created")
with open(YOLO_FORMAT_PATH + '/' + 'test.txt', 'w') as test_txt:
for path in paths_test:
test_txt.write(path)
print ("[test.txt] is created")


적당한 툴을 이용해 간편하게 해도 되고 위에 작성된 코드를 통해 손쉽게 생성할 수 있습니다. 또한 직접 타이핑해도 무방합니다. 중요한건 해당 파일이 경로를 잘 나타내도록 정확하게 타이핑해야 오류가 나지 않습니다.
/content/gdrive/My Drive/ ~ / img.jp 의 형태로 본인의 개발 환경에 맞게 설정하면 되겠습니다.
3.2 구글 드라이브 연동 및 라벨링 파일 불러오기
from google.colab import drive
drive.mount('/content/gdrive')!ls -la "/content/gdrive/My Drive"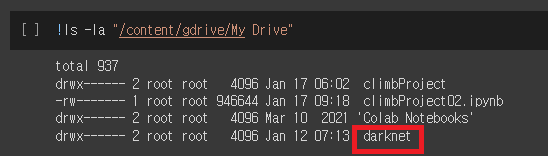
구글 드라이브 연동 후 ls 명령어로 이전에 설치해둔 다크넷이 잘 설치되었는지 확인합니다.
%tensorflow_version 2.x
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
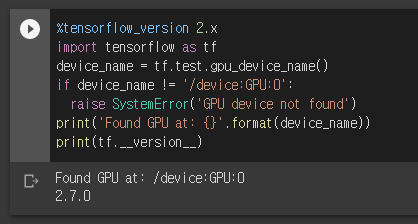
print(tf.__version__)텐서플로우 모듈을 선언하고 GPU가 정상적으로 작동하는지 확인합니다. 정상작동의 경우 아래의 결과를 출력하게 됩니다. 당연하겠지만 런타임 유형은 GPU로 설정해놓아야 합니다.
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import math
import os
import cv2
#-- batch size, epochs 등 파라미터 선언
batch_size = 128
num_classes = 0
epochs = 100
CW = 32
CH = 32
CD = 3
model_name = 'model.h5' #-- 생성될 학습 모델 이름
COLAB_DARKNET_PATH = '/content/gdrive/My Drive/climbProject' #-- 본인 환경에 맞게 경로 변경
YOLO_IMAGE_PATH = COLAB_DARKNET_PATH + '/test_2/' #-- 본인 환경에 맞게 경로 변경
YOLO_FORMAT_PATH = COLAB_DARKNET_PATH + '/test_2/' #-- 본인 환경에 맞게 경로 변경
classes = []
train_images = []
train_labels = []
test_images = []
test_labels = []
sample_test_image = 'sample_test.jpg'
sample_test_label = 0학습하기전의 전처리 과정
파라미터는 본인의 의도와 부합하게 설정해야하며 경로 설정으로 오류가 생길 수 있으니 꼭 확인하면서 진행합니다.
#-- 보여질 이미지에 넘버링하는 함수
def show_sample(images, labels, sample_count=25):
#-- {sample_count}개의 이미지를 사용하여 정사각형 생성
grid_count = math.ceil(math.ceil(math.sqrt(sample_count)))
grid_count = min(grid_count, len(images), len(labels))
plt.figure(figsize=(2*grid_count, 2*grid_count))
for i in range(sample_count):
plt.subplot(grid_count, grid_count, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
image = cv2.cvtColor(images[i], cv2.COLOR_BGR2RGB)
plt.imshow(image, cmap=plt.cm.gray)
plt.xlabel(labels[i])
plt.show()
#-- 코랩에서 파일 다운로드
def download(path):
try:
from google.colab import files
files.download(path)
except ImportError:
import os
print('Error download:', os.path.join(os.getcwd(), path))
#-- Yolo 포맷의 이미지 ROI 좌표를 가져오는 함수
def getROI(size, box):
width_ratio = size[1]
height_ratio = size[0]
x = float(box[1]) * width_ratio
y = float(box[2]) * height_ratio
w = float(box[3]) * width_ratio
h = float(box[4]) * height_ratio
half_width = w/2.0
half_height = h/2.0
startX = int(x-half_width)
startY = int(y-half_height)
endX = int(x+half_width)
endY = int(y+half_height)
return (startY, endY, startX, endX)
def imShow(path):
fig = plt.gcf()
#fig.set_size_inches(18, 10)
plt.axis("off")
plt.imshow(cv2.cvtColor(path, cv2.COLOR_BGR2RGB))
plt.show()테스트를 위한 함수 선언
with open(YOLO_FORMAT_PATH + 'classes.txt', 'r') as txt:
for line in txt:
name = line.replace("\n", "")
classes.append(name)
num_classes += 1
print (classes, num_classes)클래스 파일에서 학습에 필요한 클래스들을 불러옵니다.
image_count = 0
with open(YOLO_FORMAT_PATH + 'train.txt', 'r') as txt:
for line in txt:
image_path = line.replace("\n", "")
img = cv2.imread(image_path)
size = img.shape[:2]
text_path = image_path[:-4] + '.txt'
with open(text_path, 'r') as txt:
for line in txt:
box = line.split()
(startY, endY, startX, endX) = getROI(size, box)
image = cv2.resize(img[startY:endY, startX:endX], (CW,CH), interpolation = cv2.INTER_AREA)
#gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
#equ = cv2.equalizeHist(gray)
#imShow(image)
#print(int(box[0]))
#-- 데이터와 레이블 목록을 업데이트
train_images.append(image)
train_labels.append(int(box[0]))
image_count += 1
#-- 데이터와 레이블을 numpy 배열로 변환
train_images = np.array(train_images)
train_labels = np.array(train_labels)
#-- [0,1] 범위까지 데이터를 축척
train_images = train_images.astype("float32") / 255.0
#-- train 레이블을 one-hot 인코딩
train_labels = keras.utils.to_categorical(train_labels, num_classes)
print ('%d images added' % image_count)첫 번째로 각 경로가 작성된 train.txt 파일을 통해 train 파일들을 불러옵니다.
image_count = 0
with open(YOLO_FORMAT_PATH + 'test.txt', 'r') as txt:
for line in txt:
image_path = line.replace("\n", "")
img = cv2.imread(image_path)
size = img.shape[:2]
text_path = image_path[:-4] + '.txt'
with open(text_path, 'r') as txt:
for line in txt:
box = line.split()
(startY, endY, startX, endX) = getROI(size, box)
image = cv2.resize(img[startY:endY, startX:endX], (CW,CH), interpolation = cv2.INTER_AREA)
#gray = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
#equ = cv2.equalizeHist(gray)
#imShow(image)
#print(int(box[0]))
#-- 데이터와 레이블 목록을 업데이트
test_images.append(image)
test_labels.append(int(box[0]))
#-- 테스트를 위해 마지막 이미지를 남겨둠
cv2.imwrite(sample_test_image, image)
sample_test_label = int(box[0])
image_count += 1
#-- 데이터와 레이블을 numpy 배열로 변환
test_images = np.array(test_images)
test_labels = np.array(test_labels)
#-- [0,1] 범위까지 데이터 축척
test_images = test_images.astype("float32") / 255.0
#-- test 레이블을 one-hot 인코딩
test_labels = keras.utils.to_categorical(test_labels, num_classes)
print ('%d images added' % image_count)두 번째로 각 경로가 작성된 test.txt 파일을 통해 test 파일들을 불러옵니다.
#-- train 데이터셋의 이미지를 표시
show_number = len(train_images)
print('Tatal number of Images : %d' % show_number)
if (show_number > 25 ):
show_number = 25
show_sample(train_images,
['%s' % classes[np.argmax(label)] for label in train_labels], show_number)train 데이터를 통해 읽어들인 이미지들을 리사이징하여 나타냅니다.

해당 코드를 실행하면 라벨링을 토대로 클래스가 잘 분류된 모습을 볼 수 있습니다.
#-- test 데이터셋의 이미지를 표시
show_number = len(test_images)
print('Tatal number of Images : %d' % show_number)
if (show_number > 25 ):
show_number = 25
show_sample(test_images,
['%s' % classes[np.argmax(label)] for label in test_labels], show_number)마찬가지로 test 데이터셋의 이미지를 나타냅니다.
3.3 학습 및 학습파일 생성
#-- 모델 아키택처 정의
inputShape = (CH, CW, CD)
model = keras.Sequential([
keras.layers.Flatten(input_shape=inputShape),
# keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Reshape(target_shape=inputShape),
keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.Conv2D(filters=64, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Dropout(0.25),
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation=tf.nn.relu),
keras.layers.Dropout(0.5),
#-- softmax 분류기 사용
keras.layers.Dense(num_classes, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.CategoricalCrossentropy(),
metrics=['accuracy'])#-- 가장 최적의 모델을 digits_model.h5 형태로 저장
modelCheckpoint = tf.keras.callbacks.ModelCheckpoint(model_name, save_best_only=True)
#- loss 값을 모니터링할 콜백을 정의
earlyStopping = tf.keras.callbacks.EarlyStopping(monitor='val_loss',
patience=5)이제 커스텀 분류 모델을 만들도록 합니다.
#-- ealyStopping 모델을 사용하여 train 실시
history = model.fit(train_images, train_labels,
validation_data=(test_images, test_labels),
epochs=epochs, batch_size=batch_size,
callbacks=[earlyStopping,modelCheckpoint])위의 코드로 학습을 시작합니다. epochs 값이나 batch size의 경우 본인의 모델에 맞게 임의로 변경하여 사용할 수 있습니다. 또한 학습 모델도 전체적인 데이터 수가 적어 earlyStopping 모델을 사용하였으나, keras에서 제공되는 다른 모델들도 사용해볼 수 있겠습니다.
download(model_name)해당 코드로 커스텀한 모델을 다운받습니다.
#-- test 데이터셋을 통한 모델 평가
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
fig, loss_ax = plt.subplots()
fig, acc_ax = plt.subplots()
loss_ax.plot(history.history['loss'], 'ro', label='train loss')
loss_ax.plot(history.history['val_loss'], 'r:', label='val loss')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
loss_ax.legend(loc='upper left')
acc_ax.plot(history.history['accuracy'], 'bo', label='train accuracy')
acc_ax.plot(history.history['val_accuracy'], 'b:', label='val accuracy')
acc_ax.set_ylabel('accuracy')
acc_ax.legend(loc='upper left')
plt.show()번외로 테스트 데이터셋을 통해 모델 평가를 하는 부분을 추가했습니다.

제가 만든 모델에 대한 loss 값과 accuracy 값 입니다.
3.4 테스트
#-- test 데이터셋에서 이미지의 레이블을 예측합니다
predictions = model.predict(test_images)
#-- 25개의 이미지 플롯으로 test 이미지와 예측한 레이블을 나타냅니다
show_sample(test_images,
['%s : %.2f' % (classes[np.argmax(result)], result[np.argmax(result)]*100) for result in predictions],
len(predictions))이제 test 데이터를 통해 예측한 값을 확인해봅니다. 전체적으로 보기 쉽도록 25개로 이미지를 나열하여 예측한 레이블을 함께 나타냅니다.
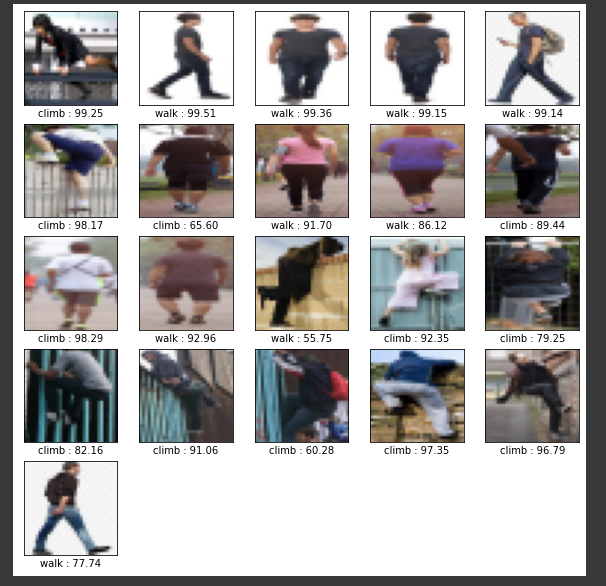
잘못 예측된 경우도 있지만 대체적으로 의도한대로 나타나는 듯 싶습니다.
selected_digit = 5
result = predictions[selected_digit]
result_number = np.argmax(result)
print('%s : %.2f' % (classes[result_number], result[result_number]*100))
imShow(test_images[selected_digit])최종적으로 하나의 이미지만을 예측해봅니다. 이미지 넘버를 설정해 원하는 이미지로 예측을 실시해봅니다.

이미지 속 월담을 98.17% 의 accuracy로 예측한 모습
코랩의 GPU 환경에서 작게나마 머신러닝을 통해 커스텀 모델을 제작해 보았습니다. 추후 영상에 적용시켜 실시간으로 감지하는 모델을 제작해보려 합니다.
'Project > Wall Climb Situation' 카테고리의 다른 글
| [Project] 월담 행위 인식 모델 - 2. 개발환경(코랩, 다크넷) 설정 (1) | 2022.01.25 |
|---|---|
| [Project] 월담 행위 인식 모델 - 1. 라벨링 및 이미지 전처리 (0) | 2022.01.24 |


댓글