
이전 포스팅에서 필요한 데이터와 라이브러리 설치를 완료하였습니다.
이번 포스팅에서는 본격적으로 모델 설계를 완성해 보겠습니다.
1.1 데이터 분석
import pandas as pd
data = pd.read_csv('BTC-USD.csv') #- 본인 환경에 맞게 경로 변경할 것
data먼저 상단의 코드를 통해 내려 받은 비트 코인 차트 데이터를 불러옵니다.

코드 실행 후 위과 같은 출력 결과를 볼 수 있습니다.
각각의 컬럼을 살펴보면
Date(날짜), Open(시가), High(고가), Low(저가), Close(종가), Adj Close(수정종가), Volume(거래량)
의 구성으로 되어있습니다. 이번 프로젝트에서는 최종으로 형성된 가격만을 활용할 계획이므로 Close 컬럼을 사용할 것입니다.
seq = data[['Close']].to_numpy()
print('최근 10일의 종가:\n', seq[0:10])
해당 코드를 통해 종가 컬럼만 따로 변수로 설정한 뒤
최근(파일 기준 22년 8월 21일) 10일 이내의 종가만 출력해 보았습니다.
import matplotlib.pyplot as plt
plt.plot(seq, color = 'r')
plt.title('Bitcoin Prices (1 year from 2021-08-08)')
plt.xlabel('Days')
plt.ylabel('Price in USD')
plt.show()
해당 컬럼에 대한 데이터를 보기 편하도록 차트 그래프로 따로 출력해 보았습니다.
(+matplotlib의 경우 일반적인 코드로는 한글 출력이 불가하므로 부득이하게 영어를 사용하였습니다. 추가적인 api 등으로 가능하나 해당 프로젝트에서는 생략하겠습니다.)
1.2 window size 및 horizon factor 설정
비트 코인 차트와 같은 금융 데이터는 시계열 데이터로서 이는 시간에 따라 변하는 동적인 데이터 입니다.
이러한 시계열 데이터는 다른 데이터와 다르게 한 번에 모든 정보를 입력(학습) 받으면 유의미한 결과를 얻기 어렵습니다.
즉 데이터의 순서(시간)가 중요하며, 이전의 있었던 순차적인 정보를 통해 향후의 사건을 예측한다고 보시면 되겠습니다.
자세한 이론 등은 다루기에는 저의 지식도 짧고 이곳에 서술하기에도 복잡하니 시계열 데이터 활용시 사용되는
주요 변수에 대해서만 간단하게 작성해보겠습니다.
먼저 window size란 데이터를 일정한 길이로 자른 샘플이라고 보시면 되겠습니다.
해당 프로젝트 데이터로 예를 들면 window size = 3일 경우 3일 분량의 비트 코인 가격 데이터 입니다.
다음 horizon factor는 쉽게 말해 얼마나 나중의 사건을 예측할건지를 설정하는 변수라고 생각하면 되겠습니다.
즉, window size = 3을 통해 3일 분량의 가격 데이터를 활용할 때 몇 일 뒤의 가격을 예측할 것인가
라고 생각하면 되겠습니다. 이 때 horizon factor = 1인 경우 하루 뒤의 가격을 예측한다고 설정하는 것 입니다.
'''
window size 기간동안의 변화(X)를 통해 horizon factor 만큼의 후의 값(Y)은?
'''
def seq2dataset(seq, window, horizon):
X = []
Y = []
for i in range(len(seq) - (window+horizon)+1):
x = seq[i:(i+window)]
y = (seq[i+window+horizon-1])
X.append(x)
Y.append(y)
return np.array(X), np.array(Y)
w = 7 #- window size
h = 1 #- horizon factor
X ,Y = seq2dataset(seq, w, h) #- w, h에 따라 데이터셋 재구성
print(X.shape, Y.shape)
window size와 horizon factor에 따라 데이터셋을 재구성 합니다.
저의 경우 w = 7, h = 1로 설정하였으며, 이에 따라 x = 7일 간의 가격 집합 데이터 / y = 7일 간의 가격 집합 데이터의 h일 후의 실제 가격 데이터 / h = 하루 뒤의 가격을 예측 이 되겠습니다.
1.3 데이터셋 분리
split = int(len(X)*0.7)
x_train = X[0:split]
y_train = Y[0:split]
x_test=X[split:]
y_test=Y[split:]여러 라이브러리의 함수로 쉽게 데이터를 학습, 테스트 데이터로 나눌 수 있으나
간단한 코드 작성으로 나누어 보았습니다.
1.4 모델 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from tensorflow import keras모델 설계에 앞서 필요한 라이브러리를 선언합니다.
저의 경우 기본적으로 tensorflow API를 사용하며 사용되는 알고리즘은 LSTM 입니다.
model = Sequential()
model.add(LSTM(units = 128, activation = 'relu',input_shape = x_train[0].shape))
model.add(Dense(1))
opt = keras.optimizers.Adam(learning_rate=0.01)
model.compile(loss = 'mae', optimizer = opt, metrics=['mae'])
history = model.fit(x_train, y_train, epochs=200, batch_size=1, validation_split=0.2)대략적인 모델 설계 구성은 다음과 같습니다.
---------------------------------------------------------------
은닉계층: 128
활성화 함수: Relu
옵티마이저: Adam (학습률: 0.01)
epochs: 200
batch size: 1
손실함수: MAE(Mean Absolute Error, 평균절대오차)
평가지표: MAE
----------------------------------------------------------------
매개변수 값에 대한 설명은 생략하며, 대부분의 시계열 데이터를 통한 모델 검증에 사용되는 MAE 지표를 적용하였습니다.
이에 대한 해석은 출력 값을 통해 설명하겠습니다. 다음 사진은 출력 예시 입니다.

최종적인 출력 부분만 캡쳐하였습니다.
1.5 모델 평가
evaluate_value = model.evaluate(x_test, y_test, verbose=0)
print("MAE 값:", evaluate_value[1])
pred = model.predict(x_test)
print("MAPE 값:", sum(abs(y_test-pred)/y_test)/len(x_test))
해당 모델에 대한 MAE 값은 약 735.91이며 MAPE 값은 약 0.03 입니다.
자세한 수학적 수식이나 해석은 생략하며, MAE의 경우 이는 예측 값에서 실제 값을 뺀 절대 값에 대한 평균 입니다. 즉, 예측한 값이 실제 값에서 얼마나 떨어져 있느냐를 나타내며 값이 작을수록 성능이 좋은 모델이라 할 수 있습니다.
다만 735.91라는 수는 다른 데이터를 통한 모델과 비교를 하기에 모호한 점이 있습니다. 예를 들어 값이 다른 비트 코인 값의 예측과 이더리움 값의 예측은 서로 스케일(값=달러)이 다르기 때문에 MAE 값이 달라질 수밖에 없습니다. 따라서 MAPE(Mean Absolute Percentage Error, 평균절대밧백분율오차)라는 해당 MAE에 대한 실제 값 대비 오차를 계산을 통해 MAE값의 성능을 비교해볼 수 있습니다. 따라서 해당 모델의 경우 MAPE 값은 0.03으로 이는 전체 정답에서 평균적으로 +-3%정도 오차가 있다 볼 수 있습니다.
즉 해당 모델은 전체적으로, 예측한 값이 실제 값과 비교했을 때 평균적으로 약 735.91의 오차가 있으며 이는 +-3% 정도의 오차가 있다 볼 수 있습니다.
1.6 시각화
마지막으로 모델 성능에 대한 값을 시각화 하여 직관적으로 살펴볼 수 있도록 합니다.
x_range = range(len(y_test))
plt.plot(x_range, y_test[x_range])
plt.plot(x_range, pred[x_range])
plt.legend(['True prices', 'Predicted prices'], loc = 'best')
plt.ylabel('Price')
plt.xlabel('days')
plt.grid()
plt.show()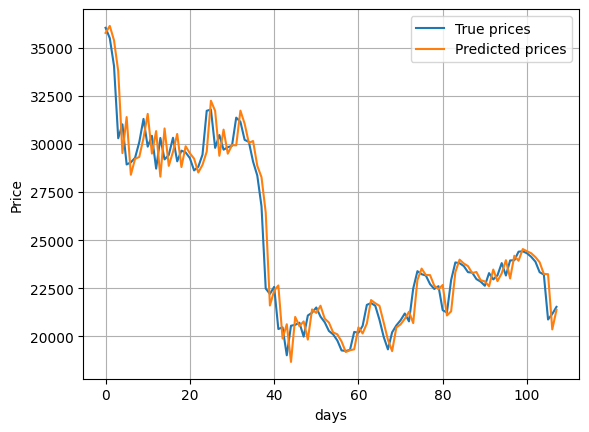
비트 코인 가격 예측 모델 설계를 통해 작게나마 시계열 데이터의 예측을 실시해보았습니다.
사실, 비트코인과 같은 암호화폐는 초 단위로 변동폭이 심하고 알 수 없는 수 많은 변수가 개입되기 때문에 이러한 데이터에는 적용이 적절하지 않다고 생각됩니다. 다만 대략적으로 이런 방법으로 활용된다는 예제로서 다루어 보는 시간이었습니다.
다음 프로젝트에서는 다중 데이터를 통한 예측 프로젝트를 계획해 보겠습니다.
'Project > Bitcoin price Predict' 카테고리의 다른 글
| [Project] 비트코인 가격 예측 모델 - 1 (2) | 2022.08.22 |
|---|

댓글