반응형

https://prlabhotelshoe.tistory.com/33
[YOLO] 영상 객체 인식 - 번외: 원하는 객체만 검출
https://prlabhotelshoe.tistory.com/15 [YOLO] 영상 객체 인식 컴퓨터 비전 혹은 머신러닝 등을 공부하면 한 번쯤 접하게 되는 yolo OpenCV를 활용하여 yolo 포맷을 이용해 영상 속 객체 인식 테스트를 진행해보..
prlabhotelshoe.tistory.com
이전 번외 포스팅에서 더 나아가 원하는 객체를 검출했을 경우 해당 객체를 자동적으로 캡쳐 후 저장하는 테스트를 진행해 보았습니다.
자세한 사전 세팅은 위의 링크를 통해 준비하시면 되겠습니다.
소스코드
import cv2
import numpy as np
import time # -- 프레임 계산을 위해 사용
vedio_path = './video.mp4' #-- 사용할 영상 경로
min_confidence = 0.5
def detectAndDisplay(frame):
captured_num = 0 #-- 캡쳐 프레임 간격 설정용
start_time = time.time()
img = cv2.resize(frame, None, fx=0.8, fy=0.8)
height, width, channels = img.shape
#cv2.imshow("Original Image", img)
#-- 창 크기 설정
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
#-- 탐지한 객체의 클래스 예측
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
captured_num = captured_num + 1 #-- 캡쳐 프레임 간격 설정용
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
#-- 원하는 class id 입력 / coco.names의 id에서 -1 할 것
if class_id == 0 and confidence > min_confidence:
#-- 탐지한 객체 박싱
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
#-- 검출된 객체 부분 자동 캡쳐
if captured_num % 5 == 0: #-- 본인 편의에 맞게 프레임 설정할 것
img_crop = img[y:(y+h), x:(x+w), :]
cv2.imwrite('./image'+str(captured_num)+'.png', img_crop) #-- 경로 설정
indexes = cv2.dnn.NMSBoxes(boxes, confidences, min_confidence, 0.4)
font = cv2.FONT_HERSHEY_DUPLEX
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = "{}: {:.2f}".format(classes[class_ids[i]], confidences[i]*100)
print(i, label)
color = colors[i] #-- 경계 상자 컬러 설정 / 단일 생상 사용시 (255,255,255)사용(B,G,R)
cv2.rectangle(img, (x, y), (x + w, y + h), color, 2)
cv2.putText(img, label, (x, y - 5), font, 1, color, 1)
end_time = time.time()
process_time = end_time - start_time
print("=== A frame took {:.3f} seconds".format(process_time))
cv2.imshow("YOLO test", img)
#-- yolo 포맷 및 클래스명 불러오기
model_file = './yolov3.weights' #-- 본인 개발 환경에 맞게 변경할 것
config_file = './yolov3.cfg' #-- 본인 개발 환경에 맞게 변경할 것
net = cv2.dnn.readNet(model_file, config_file)
#-- GPU 사용
#net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
#net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
#-- 클래스(names파일) 오픈 / 본인 개발 환경에 맞게 변경할 것
classes = []
with open("./coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
colors = np.random.uniform(0, 255, size=(len(classes), 3))
#-- 비디오 활성화
cap = cv2.VideoCapture(vedio_path) #-- 웹캠 사용시 vedio_path를 0 으로 변경
if not cap.isOpened:
print('--(!)Error opening video capture')
exit(0)
while True:
ret, frame = cap.read()
if frame is None:
print('--(!) No captured frame -- Break!')
break
detectAndDisplay(frame)
#-- q 입력시 종료
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()소스코드는 이전의 것과 크게 다를것은 없습니다. 각주를 통해 설정값만 본인 편의에 맞게 설정하면 되겠습니다.
테스트
테스트용 동영상은 이전 포스팅의 것을 그대로 활용하였습니다. 해당 영상을 통해 검출된 객체들을 자동으로 캡쳐하여 저장해보겠습니다.
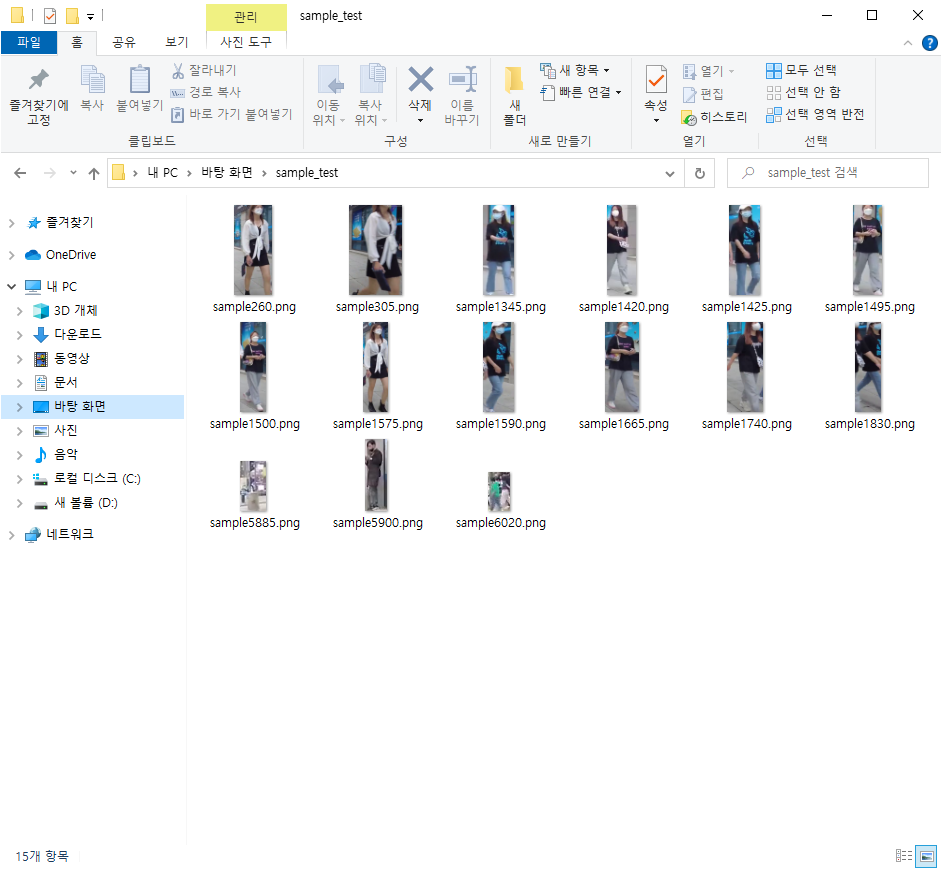
코드 작동 후 몇 초 후에 종료하여 얻은 검출된 객체 이미지들 입니다.
아무래도 프레임에서 직접 크롭하는지라 이미지 크기가 중구난방 이지만 이부분은 코드로 간단히 수정 가능하니 본인 편의에 맞게 수정하면 되겠습니다.
반응형
'Python > Yolo' 카테고리의 다른 글
| [YOLO] 영상 객체 인식 - 번외: 원하는 객체만 검출 (14) | 2022.03.07 |
|---|---|
| [YOLO] 이미지 객체 인식 (8) | 2022.02.23 |
| [YOLO] 영상 객체 인식 (16) | 2022.02.04 |



댓글