반응형

이전 포스팅에서 필요한 환경 구성은 모두 마쳤으며, 필요한 데이터를 웹사이트에서 크롤링하는 것까지 완료하였습니다. 이제 분석과 시각화에 앞서 필요한 데이터를 웹페이지에서 크롤링하도록 합니다.
2.1 영화 리뷰 사이트 크롤링
pip install beautifulsoup4BeautifulSoup이 설치되어 있지 않다면, 해당 커맨드를 통해 설치를 완료합니다.
from bs4 import BeautifulSoup
import urllib.request
f = open('./movie_reviews.txt', 'w', encoding='UTF-8')
#-- 500페이지까지 크롤링
for no in range(1, 501):
url = 'https://movie.naver.com/movie/point/af/list.naver?&page=%d' % no
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
reviews = soup.select('tbody > tr > td.title')
for rev in reviews:
rev_lst = []
title = rev.select_one('a.movie').text.strip()
score = rev.select_one('div.list_netizen_score > em').text.strip()
comment = rev.select_one('br').next_sibling.strip()
#-- 긍정/부정 리뷰 레이블 설정
if int(score) >= 8 :
label = 1 #-- 긍정 리뷰 (8~10점)
elif int(score) <= 4 :
label = 0 #-- 부정 리뷰 (0~4점)
else :
label = 2
f.write(f'{title}\t{score}\t{comment}\t{label}\n')
f.close()네이버 영화 페이지의 리뷰들을 txt 파일로 크롤링합니다. 감정 분석을 위해 긍정 리뷰와 부정 리뷰를 평점을 통해 구분하였고 8 ~ 10점은 긍정(1), 0 ~ 4점은 부정(0), 그 외는 (2)로 레이블을 작성 하였습니다.

코드를 실행하면 movie_reviews.txt 파일이 생성되고 실행시키면 위와 같이 영화명, 평점, 리뷰, 레이블이 작성된 것을 확인할 수 있습니다.
import pandas as pd
data = pd.read_csv('./movie_reviews.txt', delimiter = '\t', names=['title', 'score', 'comment', 'label']) #-- 본인 환경에 맞게 설치 경로 변경할 것
df_data = pd.DataFrame(data)
df_data.head(10)추출한 txt 파일을 pandas를 통해 좀 더 가독성이 좋도록 csv로 읽어들입니다.
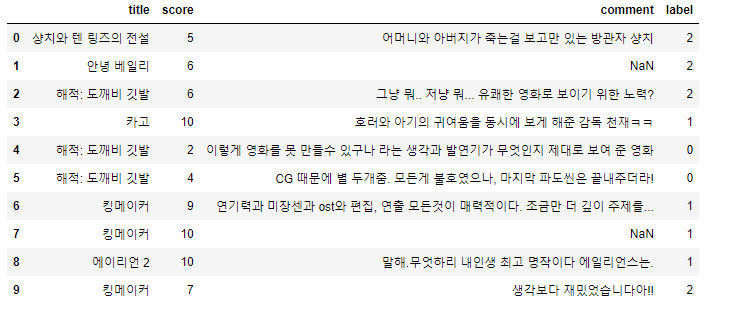
분석에 필요한 데이터를 얻었고 다음 포스팅에서 데이터 전처리와 시각화 등을 진행할 계획입니다.
반응형
'Project > Movie Review Data Visualization' 카테고리의 다른 글
| [Project] 영화 리뷰 데이터 감정분석&시각화 - 4. 빈도 분석 및 wordcloud 활용 (0) | 2022.02.09 |
|---|---|
| [Project] 영화 리뷰 데이터 감정분석&시각화 - 3. 리뷰 통계 분석 (0) | 2022.02.09 |
| [Project] 영화 리뷰 데이터 감정분석&시각화 - 1. 라이브러리(KoNLPy, wordcloud) 설치 (2) | 2022.02.09 |



댓글