
이전 포스팅에서 웹크롤링을 통해 데이터를 얻을 수 있었습니다. 해당 데이터를 바탕으로 전처리 과정과 통계를 분석해보도록 합니다.
3.1 리뷰 데이터 탐색
df_data.info()해당 코드를 통해 전체 리뷰 수를 확인합니다.

칼럼을 확인해보면 영화 제목(title), 평점(score), 리뷰(comment), 레이블(label)로 분류됨을 볼 수 있습니다. 리뷰를 보면 코멘트 없이 평점만 작성된 것도 있고 중복되는 부분도 있기 때문에 이러한 부분을 전처리 합니다.
# 코멘트가 없는 리뷰 데이터(NaN) 제거
df_reviews = df_data.dropna()
# 중복 리뷰 제거
df_reviews = df_reviews.drop_duplicates(['comment'])
df_reviews.info()
df_reviews.head(10)
이제 사이트상 작성된 리뷰(크롤링한 데이터)를 바탕으로 영화 리스트를 확인하고, 각 영화의 리뷰 수를 계산합니다.
# 영화 리스트 확인
movie_lst = df_reviews.title.unique()
print('전체 영화 편수 =', len(movie_lst))
print(movie_lst[:10])
# 각 영화 리뷰 수 계산
cnt_movie = df_reviews.title.value_counts()
cnt_movie[:20]
다음으로 각 영화들의 평점을 분석해 봅니다. 모든 리뷰에 대한 그룹별 집계를 실시하고 리뷰 수, 평균, 표준편차, 최소 평점 값, 백분위수(25%, 50%, 75%), 최대 평점 값 순으로 나열됩니다.
# 각 영화 평점 분석
info_movie = df_reviews.groupby('title')['score'].describe()
info_movie.sort_values(by=['count'], axis=0, ascending=False)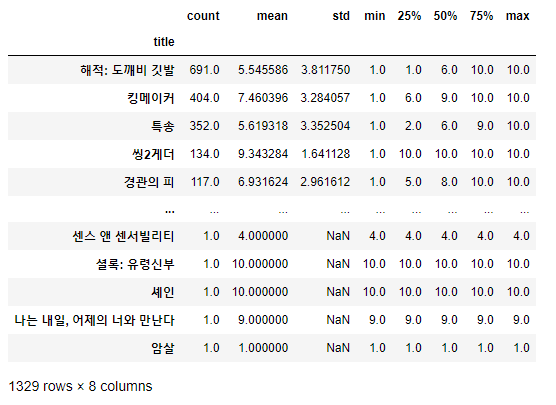
마지막으로 라벨링을 적용시켰던 데이터에 대해 긍정 리뷰와 부정 리뷰 수가 어떻게 되는지 확인해 봅니다.
# 긍정, 부정 리뷰 수
df_reviews.label.value_counts()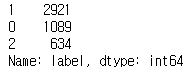
3.2 리뷰 데이터 시각화
정리된 데이터를 토대로 시각화를 진행해보도록 합니다. 먼저 필요한 라이브러리를 임포트 합니다.
%matplotlib inline #-- matplotlib를 통해 이미지를 바로 볼 수 있도록 설정
import matplotlib.pyplot as plt
#-- 한글 폰트 사용 설정
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/malgunsl.ttf"
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
#-- 그래프 마이너스 기호 표시 설정
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
시각화에 앞서 리뷰 수가 많은 상위 10개의 영화를 추출합니다.
top10 = df_reviews.title.value_counts().sort_values(ascending=False)[:10]
top10_title = top10.index.tolist()
top10_reviews = df_reviews[df_reviews['title'].isin(top10_title)]
print(top10_title)
print(top10_reviews.info())
그 다음 상위 10개 영화에 대한 평균 평점을 시각화 합니다. max 값의 경우 orange 색상으로, 그 외는 lightgrey로 설정하였습니다.
#-- 평균 평점 계산
import numpy as np
movie_title = top10_reviews.title.unique().tolist() #-- 영화 제목 추출
avg_score = {} #-- {제목 : 평균} 저장
for t in movie_title:
avg = top10_reviews[top10_reviews['title'] == t]['score'].mean()
avg_score[t] = avg
plt.figure(figsize=(10, 5))
plt.title('영화 평균 평점 (top 10: 리뷰 수)\n', fontsize=17)
plt.xlabel('영화 제목')
plt.ylabel('평균 평점')
plt.xticks(rotation=20)
for x, y in avg_score.items():
color = np.array_str(np.where(y == max(avg_score.values()), 'orange', 'lightgrey'))
plt.bar(x, y, color=color)
plt.text(x, y, '%.2f' % y,
horizontalalignment='center',
verticalalignment='bottom')
plt.show()
또 평점 분포도를 통해 평점의 분포를 대략적으로 확인해 볼 수 있도록 합니다. 붉은 색 점선을 통해 평균 또한 알 수 있도록 하였습니다.
import math
fig, axs = plt.subplots(5, 2, figsize=(15, 25))
axs = axs.flatten()
for title, avg, ax in zip(avg_score.keys(), avg_score.values(), axs):
num_reviews = len(top10_reviews[top10_reviews['title'] == title])
x = np.arange(num_reviews)
y = top10_reviews[top10_reviews['title'] == title]['score']
ax.set_title('\n%s (%d명)' % (title, num_reviews) , fontsize=15)
ax.set_ylim(0, 10.5, 2)
ax.plot(x, y, 'o')
ax.axhline(avg, color='red', linestyle='--') #-- 평균 점선 나타내기
plt.show()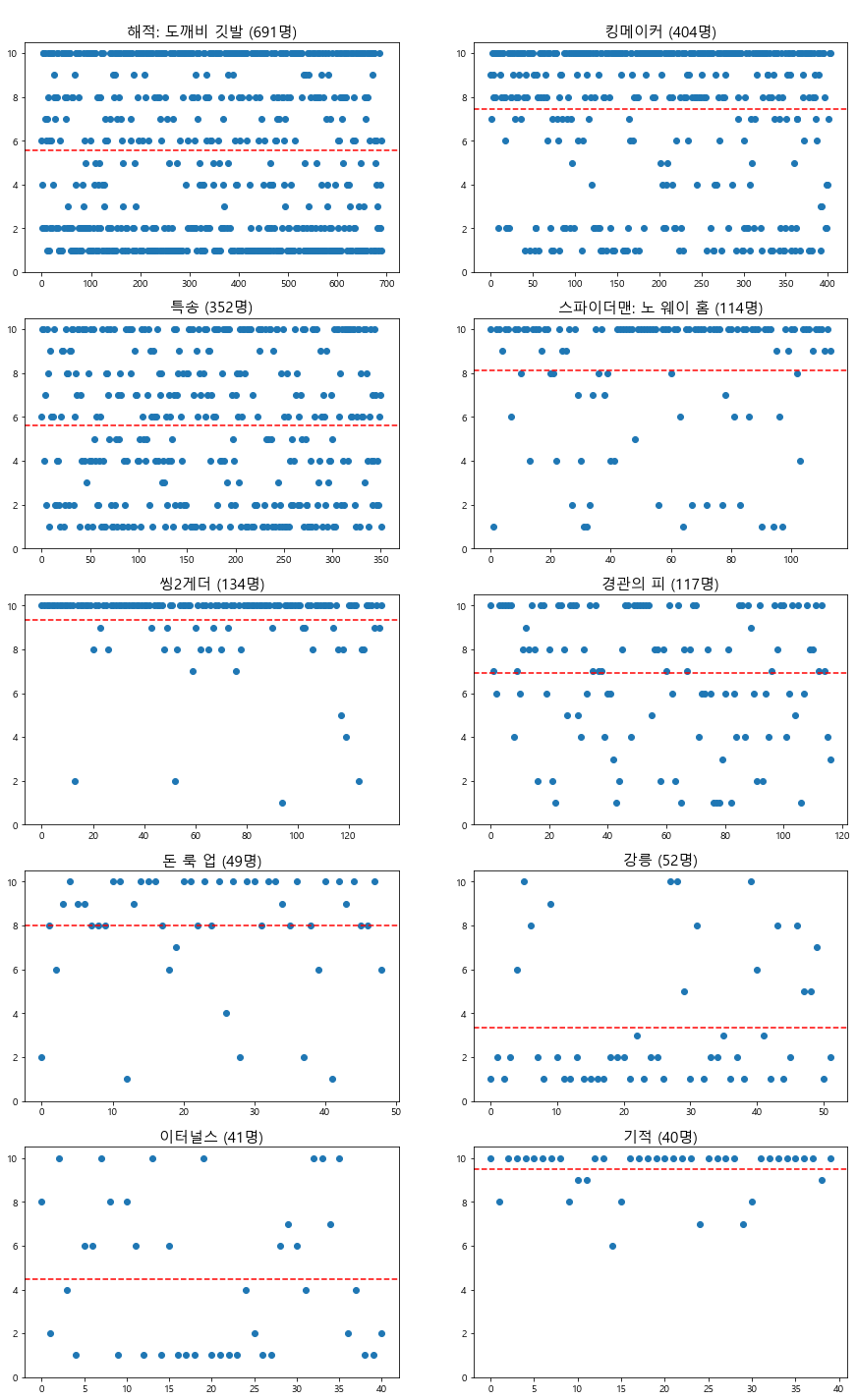
마지막으로 원형 차트를 통해 시각화를 해봅니다. 레이블한 긍정 리뷰의 경우 pink, 부정 리뷰의 경우 gold, 그 외는 whitesmoke 로 나타내었습니다.
import math
fig, axs = plt.subplots(5, 2, figsize=(15, 25))
axs = axs.flatten()
colors = ['pink', 'gold', 'whitesmoke']
labels=['1 (8~10점)', '0 (1~4점)', '2 (5~7점)']
for title,ax in zip(avg_score.keys(), axs):
num_reviews = len(top10_reviews[top10_reviews['title'] == title])
values = top10_reviews[top10_reviews['title'] == title]['label'].value_counts()
ax.set_title('\n%s (%d명)' % (title, num_reviews) , fontsize=15)
ax.pie(values,
autopct='%1.1f%%',
colors=colors,
shadow=True,
startangle=90)
ax.axis('equal')
plt.show()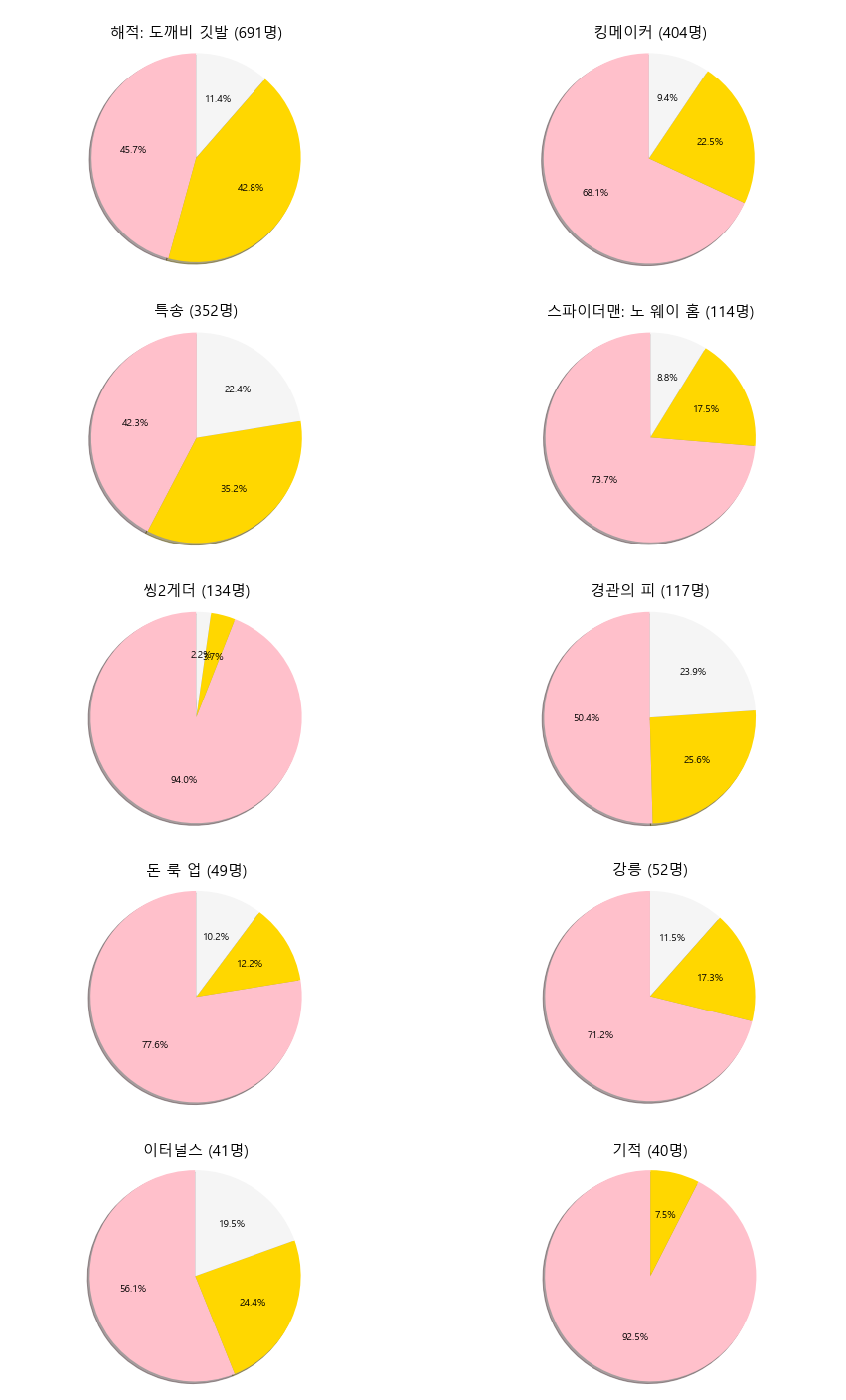
'Project > Movie Review Data Visualization' 카테고리의 다른 글
| [Project] 영화 리뷰 데이터 감정분석&시각화 - 4. 빈도 분석 및 wordcloud 활용 (0) | 2022.02.09 |
|---|---|
| [Project] 영화 리뷰 데이터 감정분석&시각화 - 2. 웹페이지 크롤링 (0) | 2022.02.09 |
| [Project] 영화 리뷰 데이터 감정분석&시각화 - 1. 라이브러리(KoNLPy, wordcloud) 설치 (2) | 2022.02.09 |



댓글